Learn / Blog / Article
9 lessons learned scaling Hotjar's tech architecture to handle 21,875,000 requests per hour
We’re extremely ambitious - our goal is to have Hotjar installed on 10 million sites. Having such a bold vision whilst taking a freemium approach presents huge technical challenges. How does an engineering team build a platform that can handle hundreds of millions of requests per day, knowing that most of that traffic comes from free users? Early on, we knew the key was to do things differently and focus on building a platform that could scale.
NOTE: This article was originally published in 2018.

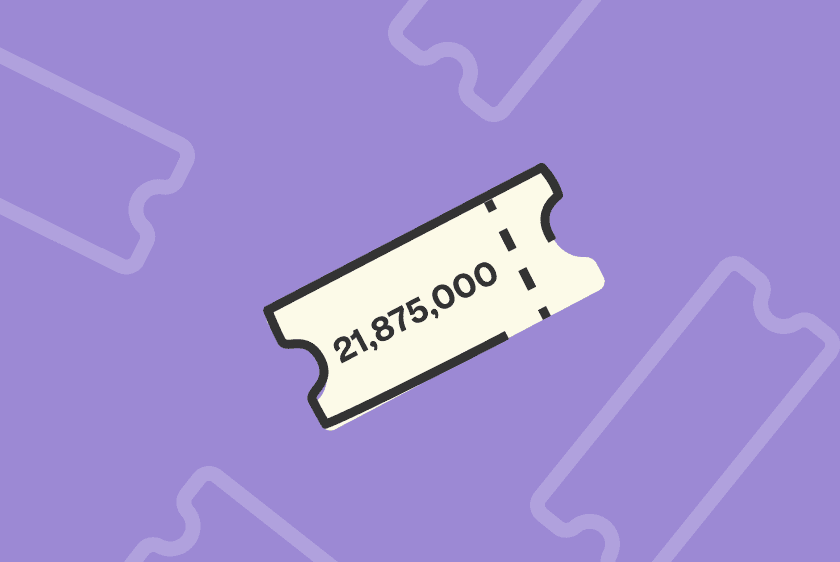
So just how much data and traffic are we dealing with?
As of writing this blog post, Hotjar has been installed on 151,036 sites. Over the past few days, we had an average of 525 million requests to our script per day. That’s 21,875,000 per hour. And 364,583 per minute. Our databases contain 37.25TB of data and grow by around 5GB per day. We write 1,500 requests to the database per second.
Keeping up with this scale requires a level of infrastructure optimization that you would never normally need. At Hotjar, engineers have a unique opportunity to work on a product that reaches millions. The challenges we face are endless, but the feeling of satisfaction we get when something we’ve built works exactly as we planned it to, for so many users, is absolutely priceless.
Tech architecture v1
Believe it or not, since we first launched Hotjar just over 2 years ago, the core technologies we use haven’t really changed. Our back-end was built in Python, our front-end was built in AngularJS and we chose PostgreSQL as our primary database.
Here’s what our architecture looked like when we first started:
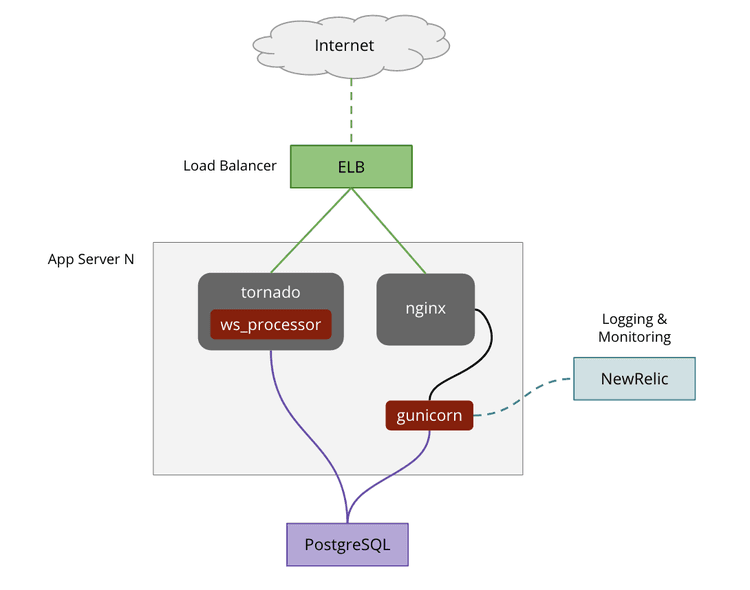
Looks simple, right? This setup had 2 instances behind a load balancer and PostgreSQL as a database. We also used NewRelic for performance management and monitoring. Early on, this architecture was perfect for us - it allowed us to scale horizontally while we tested the product with our beta users.
Although this initial setup has continued to work well as we scaled, we have had to make a number of changes to our tech infrastructure as well as added a few new technologies to our stack to be able to cope with the increasing amount of traffic.
Fast forward 2 years: our current tech architecture
Since launching the very first version of Hotjar, our tech architecture has evolved considerably. We've added much more monitoring and logging, started using different data stores and have been continually optimizing various parts of the existing setup. Here's what it looks like now:
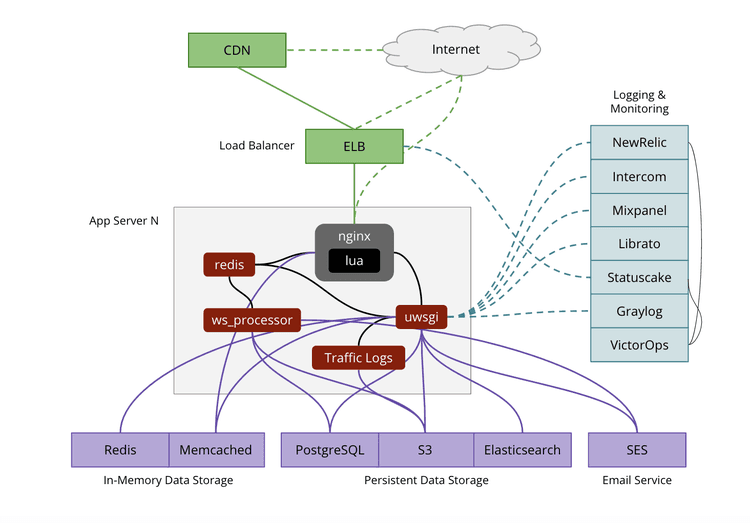
We now have 8 app servers sitting behind the Amazon ELB load balancer.
We monitor server performance using NewRelic.
We monitor real-time operations and get performance analytics from Librato.
We use StatusCake and VictorOps to notify us whenever something goes wrong.
We send events to Intercom and Mixpanel for our marketing team to use.
We log errors (both JavaScript and Python) to Graylog.
We use three types of persistent data storage: PostgreSQL, S3 and Elasticsearch.
We use Lua to process incoming data.
We use Amazon's SES service to send emails to our users.
We use Redis and Memcached for in-memory caching.
In early 2015, Hotjar experienced rapid growth and our engineers had to quickly figure out how to improve the stack to ensure it could keep handling the increasing traffic. We learned a lot of lessons as we moved from our initial structure to the one we have now. Here are a few.
The 9 lessons we learned
Lesson #1: don’t underestimate how soon you will need to grow. Build an infrastructure which enables you to quickly scale up by adding more instances under a load balancer.
Whilst we started with just two app servers having a total of 2 CPU cores and 3.4 GiB of memory, we now have a total of 8 high performance instances. That’s a total of 64 vCPUs and 120 GiB of memory to handle all incoming traffic to the app. Being able to horizontally scale up our app servers was something we wanted to be able to do from the very beginning and has been the key feature of our infrastructure which helped us scale quickly and efficiently.
Lesson #2: whenever possible, serve frequently accessed static content from a CDN. Your site performance will increase dramatically.
Just a few weeks after launching the beta, we realized serving our script from our AWS instances simply wasn’t scalable. We knew that as Hotjar became more popular, the performance would quickly degrade. Switching to a content delivery network (CDN) made a huge difference, both in terms of speed and reliability. We now serve the script through 12 different points of presence around the world.
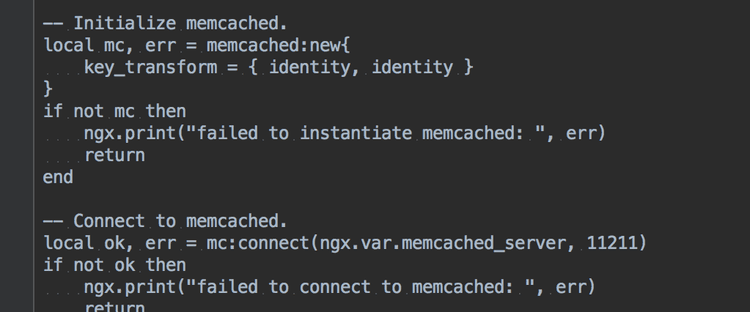
Lesson #3: sometimes you need to look beyond your core technologies for performance critical code paths.
As more users installed Hotjar, more Hotjar scripts were sending data to our servers. It was time to re-think how we processed the data we received. Should we optimize our Python code or should we look elsewhere?
Following a number of code optimizations and performance tests, we finally decided Python simply wouldn’t do. It was time to look elsewhere. We ultimately opted for Lua - a powerful, lightweight and embeddable scripting language that’s incredibly fast. Since we were able to run Lua inside nginx, we immediately benefited from incredibly high performance - our error rates instantly dropped and we were suddenly able to handle a lot more incoming requests.
Lesson #4: store data that does not require low latency and that is accessed using a primary key on cloud storage instead of your database to benefit from big cost savings.
Storing all our data in our relational database worked out fine when we first launched Hotjar. Once we started experiencing huge growth, we realized that some of the data we stored wasn’t being accessed that often. Our Chief Architect, Erik Näslund, quickly realized that we had an opportunity to save huge costs by moving that type of data to a cloud storage provider.
Since we were already using the AWS infrastructure, we migrated all the selected data onto S3 and updated our code base to fetch and put data into its new home.

Lesson #5: your primary database may not be the ideal solution for everything - be ready to move some data to other, more suitable databases as you scale.
After just 6 months of launching the beta, we were already processing 150,000recordings a day (we now process 1,000,000 recordings daily). Customers quickly started telling us that it was taking too long to browse their recording lists. We knew we needed to optimize the recordings table in PostgreSQL but even after denormalizing the table and adding all the necessary indices, it was simply taking too long to query recordings when multiple filters were selected.
It was time to look beyond PostgreSQL. Elasticsearch quickly became the top choice but switching wasn’t easy. We needed a migration plan which allowed us to keep collecting recordings whilst transferring the older recordings from PostgreSQL to Elasticsearch. To do this, we temporarily stored data in both databases, simultaneously copied over all historic data and switched to querying from ES as soon as the migration was done. Our users instantly saw a huge difference in performance and ES proved to be the right choice.
Lesson #6: think about your users - what setup do they have? Multiple users? Multiple accounts? Multiple projects? It’s important to understand how your users work early on to ensure your database schema reflects it.
When we first created Hotjar, we mistakenly assumed that most sites will be using the same domain throughout - and that is how we designed our database. Unfortunately, we soon realized that many sites used different sub domains and even domains throughout the same websites. For example, the store page for www.website.com could be store.website.com or a different domain altogether. Changes like these are easy to make early on - but very hard to make when you need to make database changes on a live environment receiving huge amounts of traffic.
To make sure the change went as smoothly as possible, our Chief Architect designed a multi-step migration plan which ensured that our users could keep using Hotjar even whilst the long migration ran. After several days, the data was finally migrated to the new format needed and another massive project was complete.
Lesson #7: sometimes, even a tiny structure change can deliver big savings, both in terms of cost and performance. If you want to cut down on costs, don't assume you will need weeks of work.
Although our script was hosted on a CDN, there was still more we could do to further optimize the script loading times. Each time a user made a change to their account, their unique script was re-generated with their new settings - which forced all users to re-download the entire 40KB script. When a script this size is being downloaded thousands of times per second, it can also mean extremely high CDN bills.
To fix this, we decided to split our script into two: A short bootstrap script which contains the user settings and another script which contains the actual Hotjar code. Each time a user makes a change, browsers only need to re-download the smaller file. This simple change instantly lowered our monthly spend and also meant that it loaded much faster for our users. Win-win!
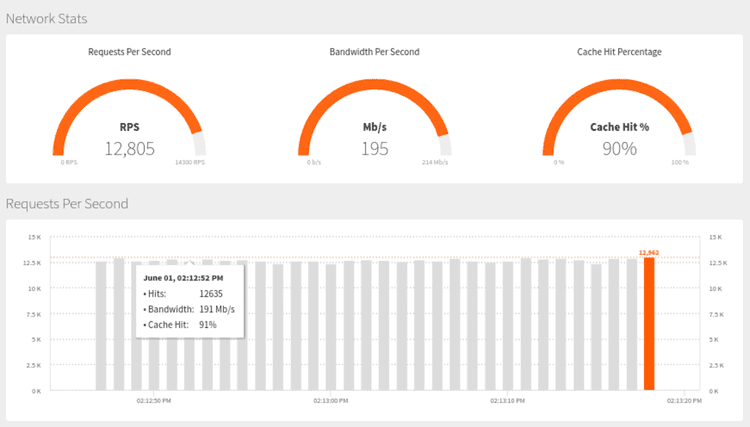
Lesson #8: though you shouldn’t over think your DB scheme too early on, make sure you have the proper monitoring set up and investigate ways of doing schema changes without downtime.
When we first started building Hotjar, we tried to build a tech infrastructure that could scale. For all our tables, we used int4 as the field type for all IDs - the standard and sensible choice in Postgres. The problem? The maximum number the ID field could store was 2,147,483,647.
A few months ago, we suddenly stopped collecting data from all sites and realized we had gone over the limit. If we only had a few thousand rows, making the field type change would have been a simple and quick update.
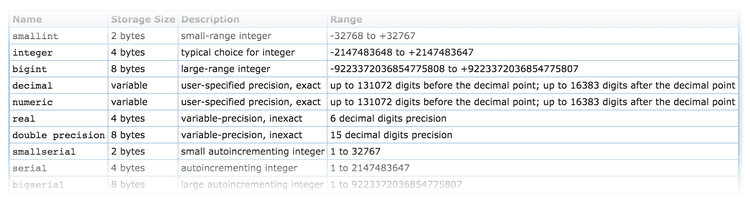
Unfortunately, with tables containing billions of rows, running a simple update could have taken days so a completely different solution was needed to keep downtime to a minimum. To solve the issue, we needed to create a separate database with the new field types, copy over the exact data from the old database to the new one, while replicating real time incoming data onto both databases. Not having the proper monitoring in place meant we weren’t able to detect the issue early enough - a mistake which cost us weeks of work.
Lesson #9: monitoring is crucial - the more monitoring you have, the quicker you can identify issues that arise from changes you’ve deployed.
We take feedback very seriously and constantly ask our users to let us know when something isn’t working as it should. When we started hearing reports about recordings not working, we were baffled - we couldn’t replicate the issue and couldn’t understand whether they were edge cases or whether the issue was happening to many users.
To help us figure it out, we spent a few hours adding additional monitoring and were quickly able to identify exactly what the issue was and just how often it was happening. Adding the monitoring not only allowed us to fix the issue but also helped the support team by cutting the amount of time they spent on investigations.
What comes next?
We've been extremely lucky to have a very skilled team of engineers working with us and helping us shape the product. Together, we have been able to tackle all the issues we've faced as we scaled up and have learned invaluable lessons along the way. However, as we continue to on-board an average of 650 users per day, we know that several more challenges lie ahead.
Want to help us tackle these challenges? Join the Hotjar engineering team!

We are always looking for full-stack developers to join our team and help Hotjar grow even further. If you’re looking for a challenge and like the sound of working remotely, you can apply here. All our developers work with an experienced multi-disciplinary team and have an opportunity to learn about new technologies and apply their skills to build incredible tools used by over 150,000 sites world wide.
Have any questions or thoughts? Or perhaps you have any lessons you wish to share about your own tech architecture?
We would love to hear them!
Related articles

Behind the scenes
The ultimate HOTSAUCE roundup
Leading minds in product, marketing, ecommerce, and UX came together over two days to shape the future of digital experiences at HOTSAUCE—Hotjar's inaugural in-person conference. Couldn’t make or want to relive the magic one more time? Take a trip through the event from the lens of the people there—Hotjar’s core planning team, speakers, and attendees—and read about their favorite moments, top learnings, and what they’re looking forward to at HOTSAUCE 2024.

Hotjar team

Behind the scenes
Celebrating Pride Month in 2023: the Hotjar Pride Panel
Here at Hotjar, we stand for an inclusive culture where our team members experience the psychological safety necessary to express themselves fully at work.
Guided by this principle, we have a long-standing tradition of celebrating Pride Month with initiatives proposed and curated by our internal LGBTQIA+ group.
Hotjar team

Behind the scenes
How to create a customer success program from scratch
Building a customer success program for the first time? Learn from Hotjar’s experiences to make your customer success program a winner.

Coleen Bachi